What's up doc ?
En France chaque année il y a plus de 10 000 décès liés à un mauvais usage des médicaments c'est-à-dire "un mauvais dosage, mauvaise prise, non-respect du traitement prescrit, interaction entre plusieurs médicaments".
Dans cette étude nous nous intéresserons au problème lié à l'interaction entre plusieurs médicaments. Dans le cadre d'un mémoire de fin d'étude de médecine, j'ai apporté ma contribution dans la construction de modèles explicatifs. Cette contribution ne fut pas vaine, car l'étudiante est devenue médecin lors de sa soutenance avec les féliciations du jury.
Récupération de données
Cette étude met le focus sur les médecins. Nous cherchons à déterminer les facteurs qui permettent d'expliquer le niveau de connaissance des risques liés à la posologie.
À partir d'une base de données de médecin, un sondage en ligne a été réalisé et a permis de récupérer près de 5656 participants. N'étant pas propriétaire des données ces dernières ne sont pas en ligne.
Les variables utilisées pour la réalisation du modèle
Variables à prédire
| Nom des variables | Signification |
|---|---|
| sge | Score général |
| sgr | Score gravité |
En fonction de questions techniques liées aux interactions médicamenteuses, deux notes ou scores sont calculés.
Le score de général va de 0 à 9 sachant que le meilleur score est de 9.
Le score de gravité va de 0 à 5 sachant que le meilleur score est de 5.
Variables explicatives
| Nom des variables | Signification |
|---|---|
| ansmedit | Savez-vous que l’ANSM édite sur son site un thésaurus actualisé des interactions médicamenteuses? |
| alertlog | Tenez-vous compte des alertes d’interaction détectées par votre logiciel de prescription ? |
| sexe | Féminin ou masculin |
| depart (param=ref ref='75') | Code départemental où vous exercez |
| faculte (param=ref ref='Paris 6') | Votre faculté d'origine |
| exercice | Votre mode d'exercice |
| zone | Zone où vous exercez |
| vidal | Utilisation de l’outil vidal |
| prescrire | Utilisation de l’outil prescrire |
| net | Utilisation d’internet |
| ansm | Utilisation de l’outil thesaurus ANSM theriaque |
| doroz | Utilisation de l’outil doroz |
| bcb | Utilisation de l’outil bcb |
| age | Quel âge avez-vous? |
| xp | Depuis combien d'années exercez-vous? |
Choix du type de modèle
Il ne s’agit pas de trouver le modèle qui permet de prévoir si un score est de 1 ou de 5. Ici les variables à
expliquer respectent un ordre, il est plus important de rechercher les déterminants qui font croitre le score c’est pourquoi nous utiliserons des modèles de régression logistique de type polytomique avec des données ordinales avec une distribution de probabilité cumulative.
Soit la variable Y : score sge ou sgr, j : niveau du score
Une probabilité cumulative pour Y est la probabilité que Y soit au-delà ou en deçà d’un niveau j.
Dans notre cas nous étudierons le cas de la probabilité cumulative pour que la probabilité que Y soit au-delà d’un niveau j c’est-à-dire que le score augmente.
Pour faciliter l’étude des variables explicatives, on réalise les modèles avec l’hypothèse des odds
proportionnels. (voir Score Test for the Proportional Odds Assumption sortie SAS).
Pour la variable explicative score sge ou sgr, le modèle est le suivant :
$$ logit [P(Y \ge j)] = \exp^{(\alpha_{j}+\beta_{x})} \ avec \ j = 1, ...., j-1 $$
avec le paramètre β décrivant les effets de x sur log odds of response de la catégorie j. Puisque nous sommes
dans le cadre d’odds proportionnels nous admettons que l’effet de x est identique pour tous les j-1 logit
cumulatif.
Pourquoi j-1 ?
Exemple pour le premier score
6 modalités et 5 courbes car la probabilité d'une des courbes = 1
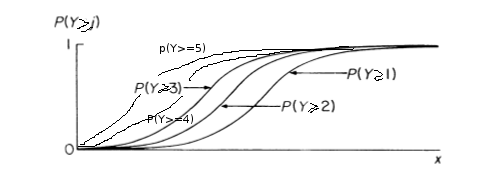
La forme de la courbe
$$ P(Y \ge j) = \frac{\exp^{(\alpha_{j}+\beta_{x})}}{1+\exp^{(\alpha_{j}+\beta_{x})}} $$
Dans les sorties SAS dans le tableau Analysis of Maximum Likehood Estimates :
α j , valeur des intercepts qui définit la position des courbes logit relatives aux scores avec j étant le niveau du score.
Les coefficients intercepts sont différents pour chaque courbe, plus j augmente plus on se déplace vers la gauche car les coefficients intercepts baissent.
βx , paramètre des variables explicatives x
L'intérêt des odds proportionnels est que pour les courbes logit ont les mêmes paramètres βx,seul change la
valeur de α pour chaque j.
Les coefficients de la courbe sont identiques pour les 5 courbes car nous avons testé l’hypothèse d’égalité des pentes (Test for the Proportional Odds Assumption) sinon pour chaque courbe nous aurions des coefficients différents et il ne serait pas possible d'avoir des odds ratios pour l'ensemble des données.
Exemple d'une des sorties
P(y>=0) = 1 pas de courbe, probabilité = 1
P(y>=1) : intercept 0.09
P(y>=2) : intercept -1.27
P(y>=3) : intercept -2.34
P(y>=4) : intercept -3.67
P(y>=5) : intercept -5.47
Les modèles sélectionnés
Modélisation d'avoir un score de gravité élevé (le plus élevé est 5)
Les sorties sas pour le modèle du score de gravité
Modèle 7 Analysis of Maximum Likehood Estimates
• le fait d'être plus âgé augmente le logit de 0.0235 et ainsi augmente la probabilité d'avoir un score de gravité plus élevé
• le fait de connaître l'existence du thésaurus présent sur le site de l'ansm augmente le logit de 0.4816 et ainsi augmente la probabilité d'avoir un score de gravité plus élevé
• le fait d'avoir fait ses études dans une université non parisienne augmente le logit de 0.2134 et ainsi augmente la probabilité d'avoir un score de gravité plus élevé
• le fait d'utiliser l'outil ansm augmente le logit de 0.8162 et ainsi augmente la probabilité d'avoir un score de gravité plus élevé
Rapport de chance relative (odds ratio)
• l'odds ratio de l'expérience est de 1.024 soit supérieur à un c'est à dire que si l'expérience augmente d'une unité la probabilité d'avoir un score de gravité plus élevé augmente, l'effet est faible mais est présent.
• lorsqu'un individu connaît l'existence du thésaurus présent sur le site de l'ansm nous avons 1,619 fois plus de chance d'avoir un niveau de gravité plus élevé par rapport à un individu qui n'en a pas sa connaissance.
• lorsque les études ont été réalisées dans une université non parisienne nous avons 1.532 plus de chance d'avoir un niveau de gravité plus élevé par rapport à un individu qui a réalisé ses études dans une université parisienne.
• lorsqu'un individu utilise l'outil ansm nous avons 2,262 fois plus de chance d'avoir un niveau de gravité plus élevé par rapport à un individu qui n'utilise pas ce dernier.
Modélisation d'avoir un score général élevé (le plus élevé est 10)
Les sorties sas pour le modèle du score général
Modèle 8 Analysis of Maximum Likehood Estimates
• le fait de connaître l'existence du thésaurus présent sur le site de l'ansm augmente le logit de 0.5971 et ainsi augmente la probabilité d'avoir un score général plus élevé
• le fait d'être de sexe masculin augmente le logit de 0.3559 et ainsi augmente la probabilité d'avoir un score général plus élevé
Rapport de chance relatives (odds ratio)
• lorsqu'un individu connaît l'existence du thésaurus présent sur le site de l'ansm nous avons 1.817 fois plus de chance
d'avoir un niveau général plus élevé par rapport à un individu qui n'en a pas sa connaissance.
• lorsque l'individu est de sexe masculin nous avons 1.427 fois de plus de chance d'avoir un niveau général plus élevé par
rapport à un individu de sexe féminin.
Pour le modèle de score de gravité nous avons 60,1% de paires concordantes, 38,1% de paires discordantes et 1.8% de paires égales.
Pour le modèle de score de général nous avons 57,1% de paires concordantes, 39,7% de paires discordantes et 3.3% de paires égales.
Autres
Détail de la signification des pourcentages de paires
p180 6.2.1 Dans l'exemple du livre l'ordre est différent avec P(Y<=j), dans nos modèles on a modélisé la probabilité d'être à un niveau plus élevé
Agreti introduction to categorical data