Using python to build a CART algorithm
In this article, I described a method how we can code CART algorithm in python language. I think it is a good exercise to build your own algorithm to increase your coding skills and tree knowledge. It's not the fastest algorithm implementation but it's enough to understand CART and object oriented programming.
Cart algorithm
In 1983, Breiman et al first described CART algorithm like classified and Regression Tree. It could be used for regression and classification of binary target.
It's a recursive algorithm, at each iteration it finds the best splitting of data which could increase the probability of predicting the target values.
Tree definition
A tree is composed of nodes. Each node could have one, two children or could be a leaf node, a node with no children.
In a list, I stored each object Node.
Tree=[node1, node2, node3, node4….]
Tree structure
To store links and paths between Nodes, I am using Breadth first Search layout.
If the node(x) has a left child the index of the child node is : node(2*x + 1)
If the node(x) has a right child the index of the child node is : node(2*x + 2)
Each node is a python object :
class Node:
def init(self,t,L,R,D,S,V,M) :
self.t=t Index of Node
self.L=L Index of Left child
self.R=R Index of right child
self.D=D Depth of the Node
self.S=S Value of split
self.V=V Feature of split
self.M=M Subset array
self.X=X Execution Flag
Splitting criteria : Gini impurity gain
$$i (n) = 1 - \sum p^2_j $$ where
$$p_j ( t) = \frac{n_t ( t)}{n ( t)}$$
is the relative proportion of category j in Node(t)
For instance, if a data set has only one class target, its gini index is zero, is a purity data set.
We have two subsets : left and right induced by the value A and feature of the split.
$$ \Delta i ( n) = i ( n) - p_{left} i ( n_{left}) - p_{right} i ( n_{right}) $$
For each features, and for each split value A, we compute gini impurity gain and we choose the partition that maximize gini impurity gain.
Example of split calculus
In this example, we considered only one feature x which is continuous.
y
|
0
|
1
|
1
|
1
|
0
|
1
|
0
|
1
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
x
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
(0+1)/2=0.5 => 0.5 split
Feature x for 0.5 split value
|
|||
0
|
1
|
||
Target y class
|
0
|
10
|
0
|
1
|
3
|
7
|
|
$$i ( n) = 1 - \left( \frac{10}{20} \right)^2 - \left( \frac{10}{20} \right)^2 = 0.5$$
$$i ( left) = 1 - \left( \frac{10}{13} \right)^2 - \left( \frac{3}{13} \right)^2 = 0.3550295$$
$$i ( right) = 1 - \left( \frac{10}{20} \right)^2 = 0$$
$$\Delta i ( n) = 0.5 - \left( \frac{13}{20} \right)0.355 = 0.2692308$$
If we have had more than one feature, we compute for each feature all the splits, and we choose the best gini impurity gain.
Code of the Cart Algorithm
GitHub link : Tree_Cart_clean.py
Function Build(Tr):
Tr : node of the tree
Ex: T[0] : node one of the list T(list of the all nodes)
Using result of ginisplit function to define or not children Node
Function Split(v,a):
v: feature, a:array
Ex: Split(2,a) : feature 2, array a
Compute maximum gini gain for one feature, it computes all the split possibility
Function Giniplit(matrix):
Matrix: Array of features
Agregate all the best split, feature, and find the best partitionning.
Function TT(depth): Main program
depth : depth of the tree, if you want a max depth of 3 you must type 2.
It's the maximum depth of root node.
Build Tree list and define node
Comparison between my Cart algorithm and sklearn Cart : Same data, same depth, same criterion
import numpy as np
import random
np.random.seed(42)
X=np.random.randint(10, size=(100, 4))
Y=np.random.randint(2, size=100)
a=np.column_stack((Y,X))
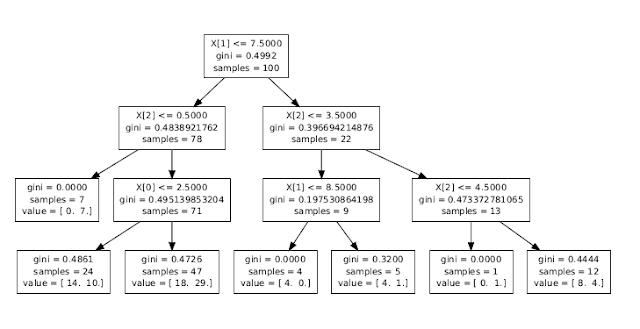
Tree from Sklearn
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='gini',max_depth=3)
clf = clf.fit(X, Y)
tree.export_graphviz(clf,out_file='tree.dot')
Tree from my Cart algorithm
#Initialisation ot the Tree list
Tree=[]
#Initialisation of Node[0]
Tree.append(Node(0,"L","R",0,"S","V",a,"X"))
#2 for 3 depth
TT(2)
#Print Tree
for index,node in enumerate(Tree):
print index,node.t,"*",node.L,node.R,"*","Depth:",node.D,node.S,len(node.M)
| Index | t | left | right | depth | split value | shape |
| 0 | 0 | 1 | 2 | 0 | 7,5 | 100 |
| 1 | 1 | 3 | 4 | 1 | 0,5 | 78 |
| 2 | 2 | 5 | 6 | 1 | 3,5 | 22 |
| 3 | 3 | * | * | 2 | * | 7 |
| 4 | 4 | 9 | 10 | 2 | 2,5 | 71 |
| 5 | 9 | * | * | 3 | * | 24 |
| 6 | 10 | * | * | 3 | * | 47 |
| 7 | 5 | 11 | 12 | 2 | 8,5 | 9 |
| 8 | 6 | 13 | 14 | 2 | 8,5 | 13 |
| 11 | 11 | * | * | 3 | * | 4 |
| 12 | 12 | * | * | 3 | * | 5 |
| 13 | 13 | * | * | 3 | * | 12 |
| 14 | 14 | * | * | 3 | * | 1 |
If we compare the tree generate by sklearn Cart and my tree generate by my Cart algorithm, they have the same results.
Usefull documents :
- Cart algorithm
- Gilles Louppe : Understanding Random Forests
To do :
- improve recursion loop in TT function to remove execution flag. This flag prevent algorithm to create children from a Node which has already been built.
- create predict function
- change the storage of array in object to rules to save memory