Récupérer les flux Twitter
Aujourd'hui pour disposer de l'information la plus fraîche il est nécessaire d'utiliser Twitter. Les grandes entreprises, les décideurs, les experts, les journalistes utilisent ce média pour communiquer, il n'est plus nécessaire d'attendre la parution de la presse pour avoir à un instant t une idée des tendances sur divers sujets.
Le fait que Bloomberg, entreprise sérieuse, propose depuis un peu plus d'une année un outil d'analyse des sentiments des tweets à destination des traders souligne le fait que l'utilisation de ces outils va se généraliser dans d'autres domaines. (Détail de la plateforme de Bloomberg)
Dans cet article, je présenterai les deux façons de récupérer les flux provenant de twitter en utilisant la librairie tweepy sous Python.
J'utiliserai pour illustrer les derniers jours de la campagne municipale parisienne opposant Nathalie Kosciusko-Morizet et Anne Hidalgo.
Dans un premier temps, il faut se déclarer développeur sur https://apps.twitter.com ainsi on pourra récupérer les différentes clefs qui nous permettront d'accéder aux flux. Je ne détaillerai pas plus la procédure qui est présente sur de nombreux forums. Un fois ces codes il faut accéder aux flux.
Il y a deux types de flux, ayant chacun des restrictions liées à l'api de twitter, le flux en direct et le flux différé.
1.Flux en direct
Nous récupérons l'ensemble des tweets pendant l'exécution du programme en appliquant des filtres qui peuvent être sur un mot clef, une langue... Pour le flux en direct, il est possible de suivre en théorie jusqu'à 400 thèmes en simultanée, la restriction est qu'il ne faut pas que l'ensemble des tweets que vous récupérez représente plus de 1 % de l'ensemble des tweets. Si ce cas se produit, il y aura une partie des tweets qui seront absents du résultat de votre requête.
Exemple de code pour le flux en direct
Dans le code ci-dessus nous récupérons le 'created_at', date de création et 'text', texte du tweet provenant du status.
Au status d'autres données sont rattachées.
Exemple provenant d'un forum
'contributors': None,
'truncated': False,
'text': 'My Top Followers in 2010: @tkang1 @serin23 @uhrunland @aliassculptor @kor0307 @yunki62. Find yours @ http://mytopfollowersin2010.com',
'in_reply_to_status_id': None,
'id': 21041793667694593,
'_api': <tweepy.api.api object="" at="" 0x6bebc50="">,
'author': <tweepy.models.user object="" at="" 0x6c16610="">,
'retweeted': False,
'coordinates': None,
'source': 'My Top Followers in 2010',
'in_reply_to_screen_name': None,
'id_str': '21041793667694593',
'retweet_count': 0,
'in_reply_to_user_id': None,
'favorited': False,
'retweeted_status': <tweepy.models.status object="" at="" 0xb2b5190="">,
'source_url': 'http://mytopfollowersin2010.com',
'user': <tweepy.models.user object="" at="" 0x6c16610="">,
'geo': None,
'in_reply_to_user_id_str': None,
'created_at': datetime.datetime(2011, 1, 1, 3, 15, 29),
'in_reply_to_status_id_str': None,
'place': None
Il est à noter que le flux étant gratuit, il est possible que lors de la capture il y ait des coupures, il faut mettre en place une stratégie pour gérer les erreurs et éviter ainsi de perdre des tweets.
2.Flux différé
Nous récupérons les flux qui ont lieu dans le passé, il est possible de remonter jusqu'à une semaine. La restriction de l'api nous impose à respecter la fréquence de 180 résultats par tranche de 15 minutes, si cette fréquence n'est pas respectée la récupération du flux s'intérrompt du fait que vous avez dépassé les quotas.
Exemple de code pour le flux différé
3.Exemple de la campagne municipale parisienne
Pour illustrer la récupération des flux sous Twitter, j'ai récupéré les flux de la campagne électorale parisienne qui opposaient Anne Hidalgo et Nathalie Kosciusko-Morizet.
L'extraction couvre la période du 26 mars 2014 au 30 mars 2014 inclus. Les données récupérées étaient par minutes et ont été agrégées par heure.
La présence du mot clef "Hildalgo" conditionne la récupération de tweet relatif à Anne Hildago.
La présence du mot clef "NKM" conditionne la récupération de tweet relatif à Nathalie Kosciusko-Morizet.
Les retweets sont inclus.
Nous dénombrons trois pics qui correspondent à :
-
le 26 mars à 18h : débat entre les deux candidates
-
le 27 mars : dernier meeting des candidates
-
le 30 mars au soir : proclamation des résultats
Hors de ces trois pics, on peut constater que les médias sociaux n'ont pas été utilisés à leur pleine mesure, nous ne sommes pas au niveau des Etats-Unis (10.3 millions de tweet pour 1h30 de débat pour la présidentielle américaine) toute proportion gardée.
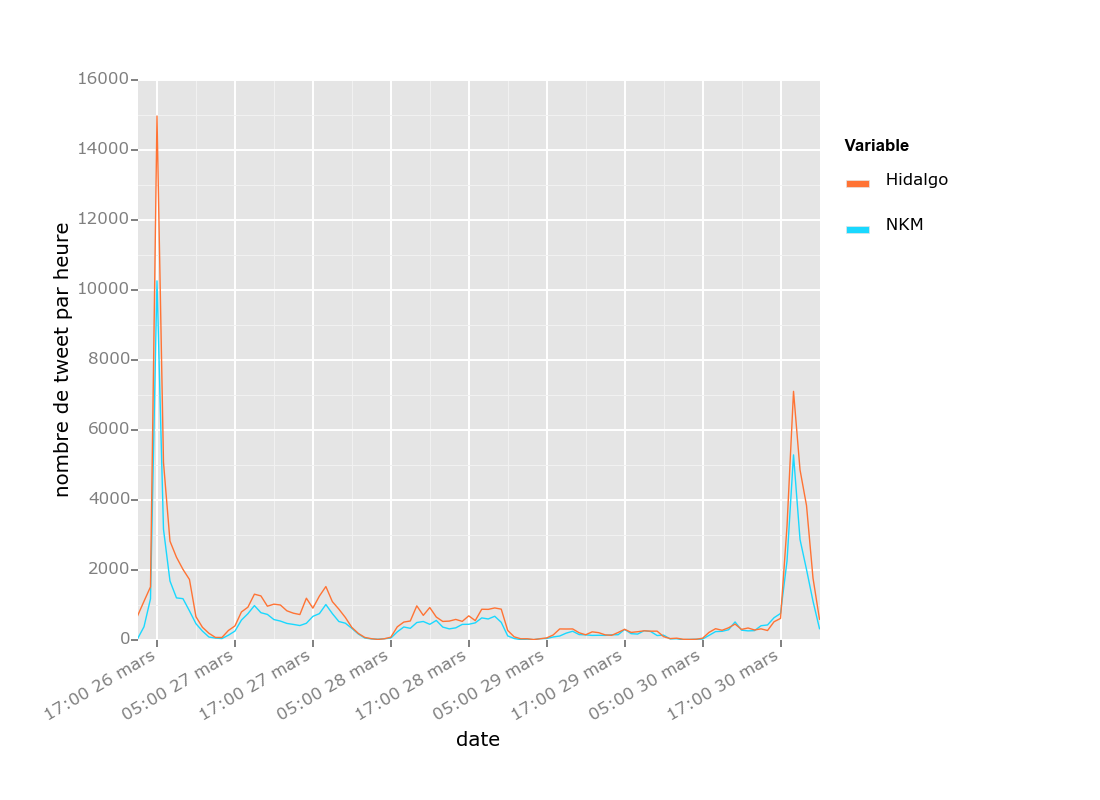
Pour réaliser ce graphique, la version de ggplot pour Python a été utilisée.