Predict census mail return rates
En 2010 des courriers ont été envoyés dans les foyers américains pour réaliser le recensement. Afin d'optimiser sa communication le bureau du recensement recherche le meilleur modèle qui sera à même de prévoir le taux de retour des plis, pour cela nous avons à notre disposition le taux de retour réel de 2010, ainsi qu'un ensemble de données sociodémographique. Les données sont au niveau des "block group" qui regroupent jusqu'à 25 000 habitants. Il a été possible d'inclure des données externes après validation par le bureau du recensement américain.
L'évaluation se fait par la moyenne absolue des erreurs pondérées par le poids des populations (weighted mean absolute error).
Résultat : le meilleur modèle a un WMAE de 2.54476, mon modèle arrive à un WMAE de 3.27624.
En classement final j'obtiens la 98e place sur un total de 244 équipes participantes.
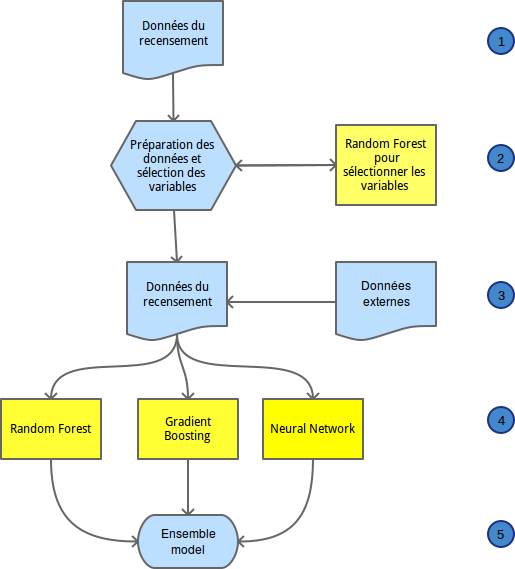
2: Avec un nombre si élevé de variables il est difficile de choisir les données qui appartiendront au modèle, la première approche qui j'avais mis en place fut de supprimer les valeurs qui étaient trop corrélées entre elles, cela fut fastidieux sans des résultats probants.
Dans mon esprit un modèle ne doit pas avoir trop de variables explicatives, car le but d'un modèle c'est de pouvoir déterminer les variables les plus déterminantes.
J'ai pour la première fois utilisés la sélection de variables en utilisant un random forest, cette technique semble utilisée dans de nombreuses situations, des utilisateurs de SAS Miner ne disposant pas de random forest utilisent R dans un premier temps pour essayer de déterminer les variables les plus explicatives.
Par un processus itératif, j'isole 40 variables.
3: Pour tenter d'améliorer le modèle, j'ai inclus les données géographiques (longitude, latitude) ainsi que les taux de chômage de chacune des zones, je n'ai pas d'amélioration significative du modèle.
4: Sur mes données j'applique les trois modèles suivants : random forest, gradient boosting ainsi que neural network.
Le gradient boosting donne les meilleures prévisions suivies des random forest et du neural network. Ne disposant pas de puissance de calcul nécessaire, je n'ai pas pu réaliser le meilleur des tunings. L'utilisation du cloud amazon EC2 devrait à l'avenir me permettre d'éviter cet écueil.
5: En combinant mes trois modèles j'ai significativement amélioré mes estimations, j'ai réalisé un ensemble modèle linéaire, une simple régression du taux de retour réel versus les taux de retour estimé par les trois modèles. L'utilisation la plus connue du modèle ensemble fut lors du concours Netfix.
Papier de référence au sujet de la combinaison de prédictions