Petit kmeans sous Matlab
La meilleure manière de comprendre un algorithme est de le programmer, dans le cas suivant je vais implémenter un algorithme de type kmeans. Pour tester ce dernier j'utilise des données fournis par le département informatique de l'université de l'Est de la Finlande.
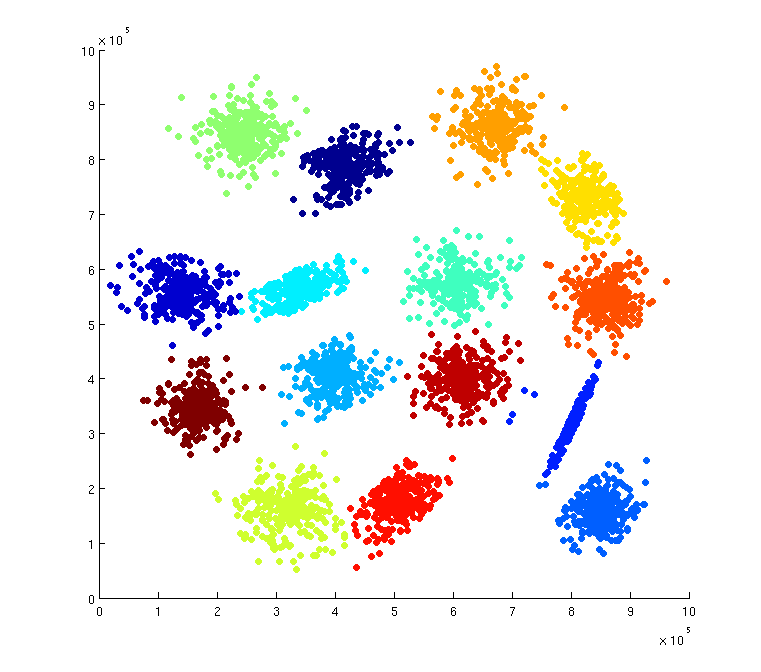
Mon choix se porte sur le dataset s1 : deux dimensions, 5 000 points avec 15 clusters.
L'algorithme est réalisé sur matlab.
Description simplifiée de l'implémentation de l'algorithme
-
définition de l'espace du nuage des points (max, min)
-
tirage aléatoire de k points correspondant au k groupe que l'on recherche dans l'espace du nuage des points
Boucle
-
calcul pour chaque point de la distance de ces derniers avec les k centres.
-
rattachement des points au groupe dont le centre est le plus proche
-
calcul du total T des distances entre chacun des points et leur centre
-
définition les nouveaux centres de chaque groupe qui sont les barycentres ou centres de gravité de chacun de groupes. (moyenne de la position des points du nuage)
- Arrêt de boucle de l'algorithme lorsque le total T n'évoluent plus c'est à dire que chacun des groupes a un centre de gravité stable
Résultat
Nous avons 15 groupes. Pour avoir une aussi bonne classification, un script a été créé qui a lancé ce programme un très grand nombre de fois et conservé la classification qui avait le total T le plus faible.
Interprétation des résultats en utilisant une analyse graphique de type silhouette
La description de cette méthodologie est issue de l'article de Peter J. Rousseeuw, Silhouettes:a graphical aid to the interpretation and validation of cluster analysis.
On considère habituellement la distance euclidienne.
Soit i, un membre du cluster
Soit a(i), la moyenne de la distance du membre i du cluster par rapport à l'ensemble des membres du cluster auquel il appartient
Soit d(i,k) : la moyenne de la distance du membre i du cluster auquel i appartient et l'ensemble des membres du cluster k.
A partir de d(i,k) on calcule l'indice de voisinage b(i), on recherche la distance d(i,k) la plus faible qui nous donne une indication de la proximité du membre i par rapport à un autre cluster.
Avec ces deux moyennes on peut construire un indice de similarité s(i):
-
Dans le premiere cas où a(i)<b(i), nous avons la distance moyenne mininal du membre i par rapport aux autres clusters qui est supérieure à la distance moyenne des membres auquel appartient i, c'est à dire que ce membre n'a pas de cluster auquel il serait plus optimal d'appartenir. Cette situation correspond à un bon classement et à un indice de similarité positif. La meilleure des situations étant le cas où l'indice de similarité est proche de 1.
-
Dans le deuxième cas où a(i)=b(i), l'indice de similarité est nulle c'est à dire qu'il existe un ou plusieurs clusters où le membre i pourrait aussi appartenir.
-
Dans le troisième cas où a(i)>b(i), nous avons la distance moyenne minimal du membre i par rapport aux autres clusters qui est inférieure à la distance moyenne des membres auqel appartient i, c'est à dire que ce membre n'est pas dans le cluster le plus optimal. Cette situation correspond à un mauvais classement et à un indice de similarité négatif. La plus mauvaise des situations étant le cas où l'indice de similarité est proche de -1.
Résulat répresentation graphique silhouette : fonction inclue dans matlab
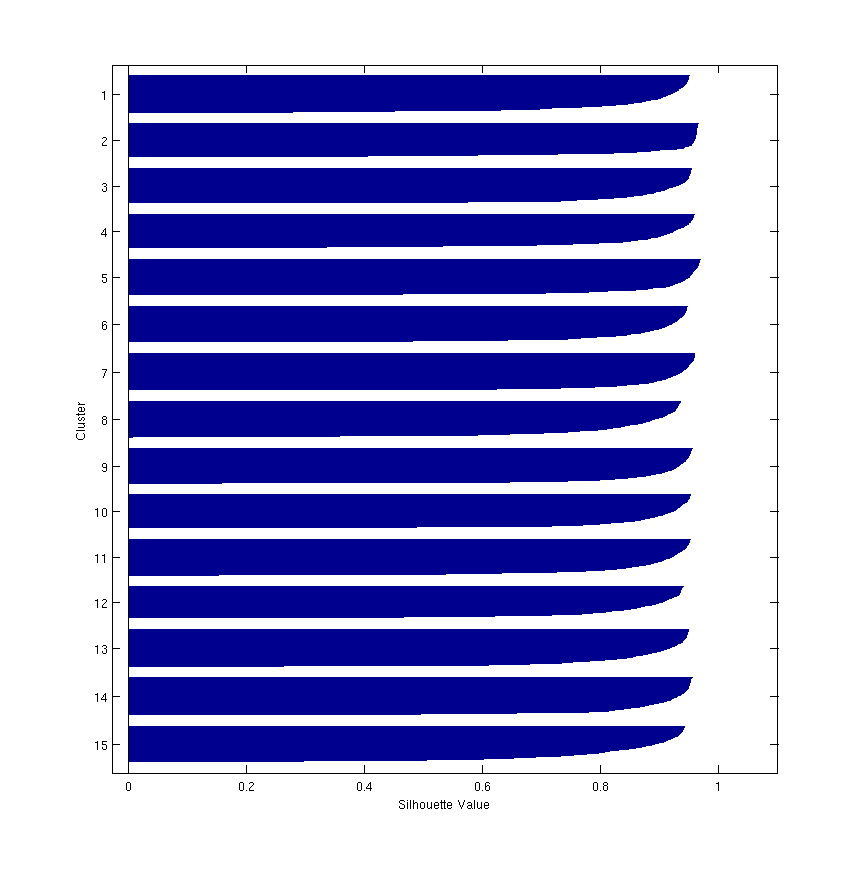
A noter que pour chaque cluster, les indices de similarité des membres i sont classés par ordre décroissant.
Cette réprésentation graphique nous permet de constater que le nombre de cluster est conforme et que le classement est bonne qualité, la majorité des membres de chaque cluster a un indice de similarité supérieur à 0.75.