Heritage Provider Network Health Prize
L'Heritage Provider Network Health Prize est une compétition qui a pour objectif de créer un modèle qui sera à même de prévoir le nombre de jours d'hospitalisation à partir de données historiques.
À partir des données historiques d'un patient (nombre et type de consultation, prise de médicaments, catégories de maladie...) à la période n, nous devons estimer le nombre de jours d'hospitalisation à la période n+1.
Pour cela nous disposons de données années 1 avec le nombre de jours d'hospitalisation années 2, de données années 2 avec le nombre de jours d'hospitalisation années 3 et enfin de données années 3 à partir desquelles on estimera le nombre de jours d'hospitalisation années 4.
J'utilise les données années 1 avec le nombre de jours d'hospitalisation années 2 en échantillon d'apprentissage.
J'utilise les données années 2 avec le nombre de jours d'hospitalisation années 3 en échantillon de test.
Le but est de minimiser le score suivant :
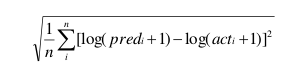
Soit : i : un individu, n : le total d'individu, pred : prévision du nombre de jours hospitalisés, act : le nombre de jours passés à l’hôpital.
Résultat : le meilleur modèle a un score de 0.461197, mon modèle arrive à un score de 0.470774.
En classement final, j'obtiens la 241e place sur un total de 1358 équipes participantes.
1.Action sur les données
-
la distribution de DaysinHospital est asymétrique à droite, en réalisant une transformation log je limite cet effet
-
pour réaliser un modèle, il faut que l'échantillon d'apprentissage, de test et sur lequel on applique le modèle soit proche or les variables relatives au délai de paiement ont des moyennes et des variances très différentes selon les échantillons, je décide de les exclure
2.Les meilleurs modèles
À la suite de nombreuses estimations et modèles, je sélectionne les 4 modèles suivants :
| Modèle | Score | Paramètres |
| Régression linéaire | 0,4761 | Stepwise sous SAS |
| Gradient Boosting | 0,472 | distribution="gaussian", n.trees=600, shrinkage=0.01, interaction.depth=12, Bag.fraction = 0.5,train.fraction = 0.5,n.minobsinnode = 50, cv.folds = 1, |
| Random Forest | 0,4786 | ntree=200, do.trace=T, sampsize=20000 |
| Regularized Greedy Forest | 0,4715 | reg_L2=1 # Regularization parameter loss=LS # Square loss test_interval=100 # Test (and save) models every time 100 leaves are added. max_leaf_forest=500 |
3.Ensemble modèle
La combinaison de différents modèles permet de réduire l'erreur c'est pourquoi à partir des quatre meilleurs modèles je construis un ensemble modèle.
Il faut trouver un modèle qui ne suridentifie pas l'échantillon d'apprentissage et ainsi ne pas fait augmenter l'erreur de l'échantillon de test lors de l'application du modèle sur ce dernier.
La régression linéaire donne une erreur de prévision très faible à partir de l'échantillon d'apprentissage (score : 0.28) mais fait augmenter l'erreur de l'échantillon du test (score : 0.51). Il y a donc ici sur-apprentissage.
Un ensemble modèle étant constitué de la combinaison de différents modèles, il me faut trouver la meilleure combinaison.
À travers un algorithme qui calcule l'erreur sur l'échantillon d'apprentissage et sur l'échantillon de test pour chacune des combinaisons, j'ai trouvé la combinaison suivante :
| Poids | |
| Régression linéaire | 8 |
| Gradient Boosting | 34 |
| Random Forest | 1 |
| Regularized Greedy Forest | 57 |
L'algorithme mettra plus de 13 heures pour calculer plus de 160 000 combinaisons sous R.
Le score de notre ensemble modèle est de 0.470774.
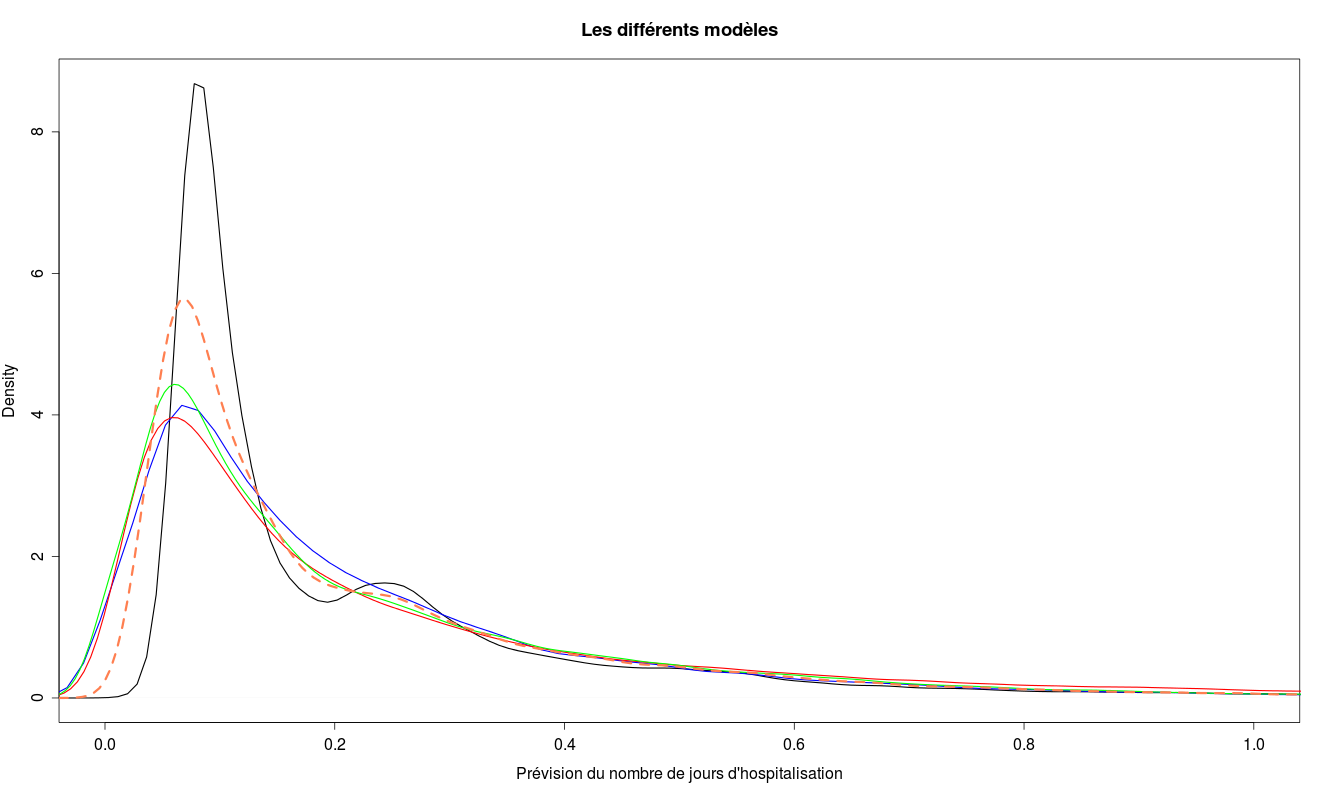
régression linéaire : bleu
gradient boosting : gris
random forest : rouge,
regularized greedy forest : vert
ensemble modèle : rouge pointillé