Give Me Some Credit
Il faut prévoir la probabilité qu'un client aura des difficultés de paiement les deux années suivant la contraction du crédit, pour cela nous disposons de l'historique de 250 000 emprunteurs.
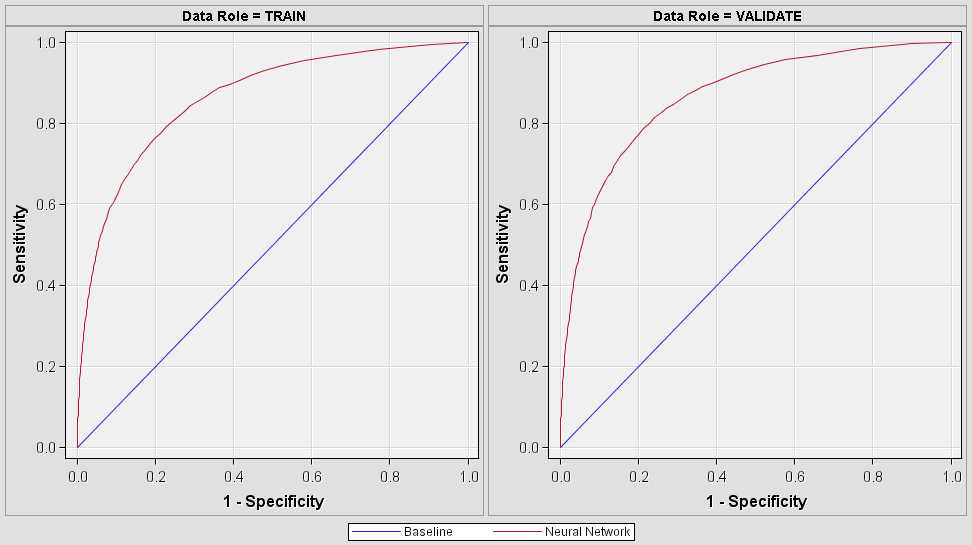
Le meilleur modèle sera celui qui aura la sensitivité la plus élevée (taux de vrai positif) et la (1-specificité (taux de faux positif) le plus faible. On recherche donc l'index ROC le plus élevé cela sera le score du modèle.
Résultat : le meilleur modèle a un ROC index de 0.869558, mon modèle obtient un ROC index de 0.853525. Je ne suis pas dans le classement final, le modèle ayant été réalisé hors compétition.
1.Échantillon et transformation des variables
Nous avons une table cs-training de 150 000 lignes sur laquelle nous allons réaliser le modèle et une autre table cs-test de 101 503 sur laquelle nous allons appliquer le modèle.
Il faut prévoir si Seriousdlqin2yrs sera Y ou N
Dictionnaire des données
| Variable Name | Description | Type |
| SeriousDlqin2yrs | Paiement minimum réalisé sur l'emprunt après 2 années | Y/N |
| RevolUtilOfUnsecuredLines | Ensemble des crédits à la consommation / total maximum des crédits possibles | pourcentage |
| age | Age de l'emprunter | integer |
| NbTime3056DaysPastDueNotWorse | Nombre de fois où le paiement minimum n'a pas été réalisé sur une période 30-59 jours ces 2 dernières années | integer |
| DebtRatio | Total des paiements de dettes, des pensions, des coûts fixes divisé par le montant des revenus mensuels | pourcentage |
| MonthlyIncome | Revenu mensuel | Real |
| NbOpenCreditLinesAndLoans | Nombre de crédits à la consommation | integer |
| NbTimes90DaysLate | Nombre de fois où il avait 90 jours et plus de retard | integer |
| NbRealEstateLoansOrLines | Nombre d’hypothèque et de prêts immobiliers | integer |
| NbTime6089DaysPastDueNotWorse | Nombre de fois où le paiement minimum n'a pas été réalisé sur une période 60-89 jours ces 2 dernières années | integer |
| NbDependents | Nombre de personnes dépendantes | integer |
NbTime3056DaysPastDueNotWorse, NbTimes90DaysLate, NbTime6089DaysPastDueNotWorse
Pour l’ensemble de ces variables, nous avons principalement des valeurs comprises en 0 et 20, cependant il existe des valeurs 96 et 98.
En l’absence de plus d’information sur ces données et sachant qu’il peut s’agir d’un codage propre à la base, nous définissons pour chaque variable où nous sommes en présence de 96 et de 98 des variables dummy respectives.
Nous créons aussi des variables dummy pour garder l’information dans les cas suivants :
Le nombre de jours est supérieur à 90
Le nombre de jours est égal à 0
Le nombre de jours devient 0 si et seulement si le nombre de jours est supérieur à 90.
Pour limiter l’impact des outliers nous réalisons une normalisation logarithmique. La détection des outliers est ici simple et ne nécessite pas l’emploi de technique de détection des outliers.
Suite à cette transformation, nous limitons l’impact des outliers : dans la définition des règles si nous réalisons un arbre de décisions dans l’initialisation des poids si nous réalisons un réseau de neurones.
NbOpenCreditLinesAndLoans
Nous créons une variable dummy pour les clients qui n’ont pas de crédit à consommation et nous procédons à une normalisation logarithme NbOpenCreditLinesAndLoans pour limiter l’impact des valeurs extrêmes.
NbRealEstateLoansOrLines
Il n’y pas de variable aberrante, pour limiter l’impact des valeurs extrêmes nous réalisons une normalisation logarithme.
NbDependents
Il y a beaucoup de données manquantes. Nous créons une variable dummy pour garder l’information Na. A la suite de la création de la dummy, les valeurs en Na sont alors remplacées par 0 pour la variable NbDependents.
Il n’a pas de valeurs extrêmes qui nécessitent une normalisation.
Création d’une nouvelle variable : Le nombre de défaut
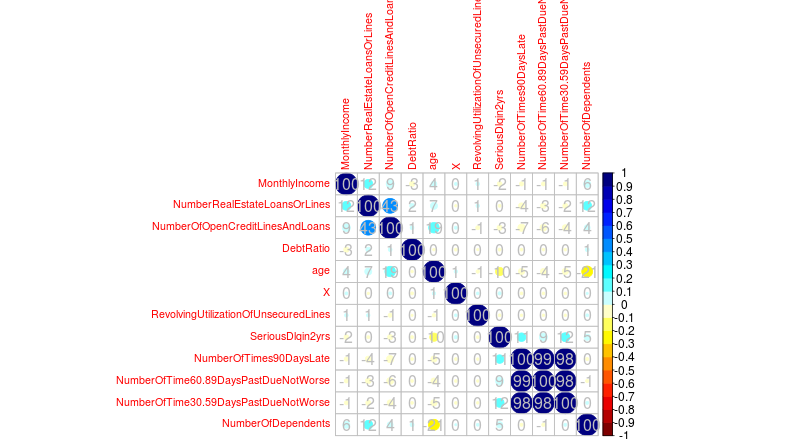
Les variables NbTime3056DaysPastDueNotWorse, NbTimes6089DaysPastDueNotWorse et NbTime6089DaysPastDueNotWorse sont fortement corrélés à la variable qu’il faut expliquer : SeriousDlquin2yrs (voir matrice de corrélation en annexe). Dans un premier temps,nous aurions pu penser qu’il fallait supprimer un ou deux de ces variables, mais nous aurions perdu l’information du nombre de défaut
2.Modèle
A la suite de différentes modélisations il en ressort que le réseau de neurons donne la meilleure estimation du risque de défaillance avec un ROC index de 0.8535.