Facebook : Find the robots
Each year, Facebook using Kaggle platform to find their future data scientist.
The best competitor participants could pass a job interview. The interest of this contest is the members of kaggle couldn't exchange trick and models, its imply that your rating is the real rating and not a copy/paste program, method process.
We must find if a bidder is a human or a robot with bidding data provided by Facebook.
The score is an area under the ROC curve which quantifies the overall ability of the test to discriminate between human and robot.
At the end of the competition, my score is a 0.92, near to the best score of 0.94. My rank is 198 of 989, not bad.
1. Data
We have two sets of data :
-
Bidder dataset : bidder_id, robot flag
Training dataset :
2 013 distinct bidders with 103 robots (5,11%)Testing dataset :
4 700 distinct bidders for testing dataset -
Bid dataset : bid_id, 7 656 335 transactions
We have 7.6 millions of bid_id, related to bidder_id
I group Bid dataset by bidder_id, and create engineering features.
2. Feature engineering
Time
The time is not in hours/minutes/seconds, we have to explore this feature, to simplified time feature, I divide this time by 100 000 000 000 to control the number of time value.
If we plot time value against bid_id value, we find three not joined periods.
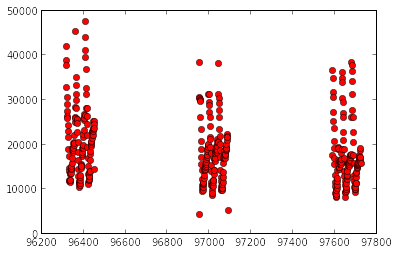
I define three periods :
- Period 1: 96319 - 96455 : 136 distinct units of new time
- Period 2: 96955 - 97092 : 137 distinct units of new time
- Period 3: 97592 - 97728 : 136 distinct units of new time
I decide to create this new features :
By bidder_id, for each period :
- Number of bid
- Number of bid at same times
- Standard deviation between bid
Other features
Number of merchandise by bidder_id
Count distinct device by bidder_id
Number of country by bidder_id
Count distinct IP by bidder_id
Count distinct URL by bidder_id
3. Overfitting
Before the end of the contest, when we have found a model, we could send our prediction to kaggle which compute your score from only 30% of data, the final score is computed with 100% of data.
If for the same model with different submission we don’t have a stable score, maybe our model is unable to generalize.
My first models were clearly overfit : my training score was near 0.99, for gradient boosting and random forest with a testing score of 0.92, when I was testing on kaggle the score was near 0.89.
To limit overfitting, I have tried to reduce the difference between training score and testing score, and lower training score from 0.99 to 0.95-0.92.
I have made ensemble models for each models, and an ensemble models of ensemble models for the final prediction.
4. Models
Neural Network :
I am using the new python libraries, https://github.com/aigamedev/scikit-neuralnetwork .
3 layers :
Maxout : units=500, pieces=2 ==> Sigmoid: units=10 ==> Softmax
The validation size is 0.4
To have a validation error near to 0.16, we must have training score greater than 0.89. I have created an iterative process which select only these models, and made an ensemble of these models. It was a long processing, more than one day to create an ensemble of 5 models because 90% of models don't respect criteria.
Gradient boosting :
I am using scikit learn libraries, http://scikit-learn.org/stable/
My model is a gradient boosting with calibrated classifier cross validation.
"When performing classification you often want not only to predict the class label, but also obtain a probability of the respective label. This probability gives you some kind of confidence on the prediction. Some models can give you poor estimates of the class probabilities and some even do not not support probability prediction. The calibration module allows you to better calibrate the probabilities of a given model, or to add support for probability prediction"
GBM:
Number estimators : 500
Max depth : 6
Learning rate: 0.001
Max features : sqrt
I have created an ensemble of calibrated classifier. For each calibrated classifier, I choose a cross validation of 10 and I repeat the procedure of calibrated classifier 100 times to get more precise result.
5. Ensemble models
To find the weight of GBM and NN which maximize the area under the ROC curve, I have used a logistic regression.
0.25Neural Network + 0.85Gradient Boosting
Code Python :